
Con motivo del congreso Hot Chips que se está celebrando en Cupertino, AMD ha proporcionado bastante más de información sobre el funcionamiento de los nuevos núcleos Zen. La semana pasada detalló por encima cosas que se sabían y dio una poca información (mínima) de la arquitectura. Hoy lo ha hecho de una manera mucho más técnica, por lo que a muchos os sonará a chino lo que viene a continuación.
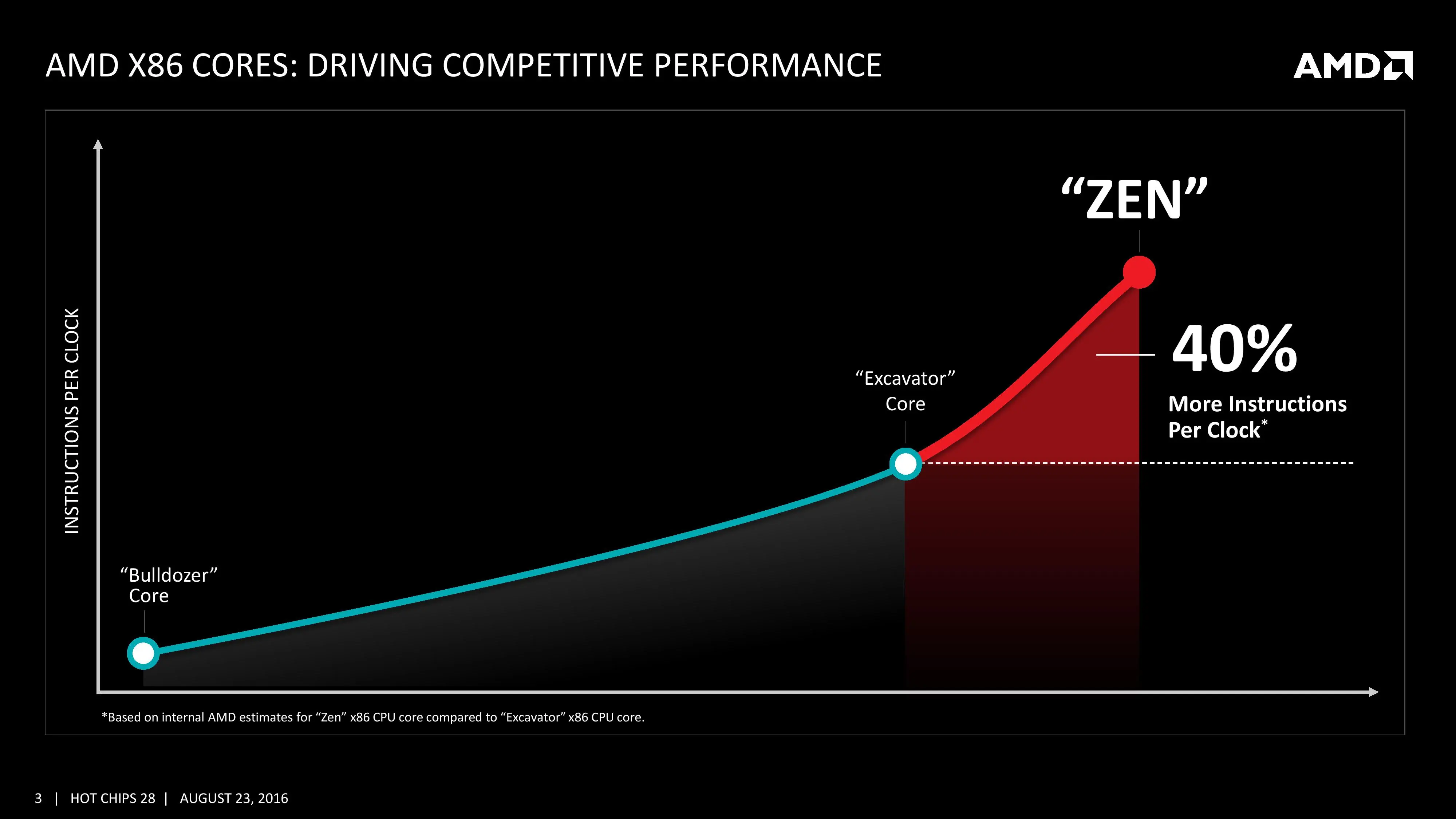
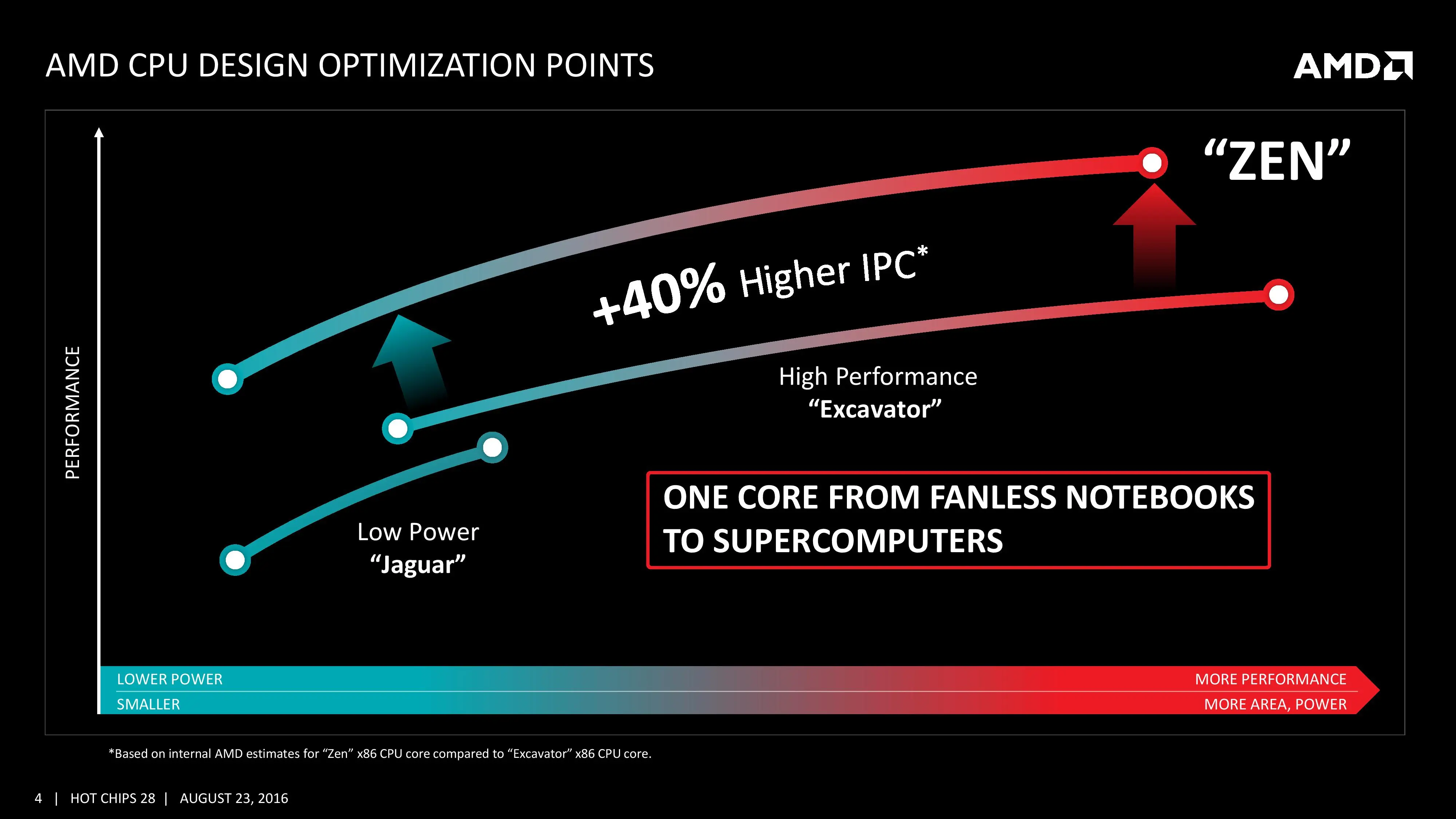
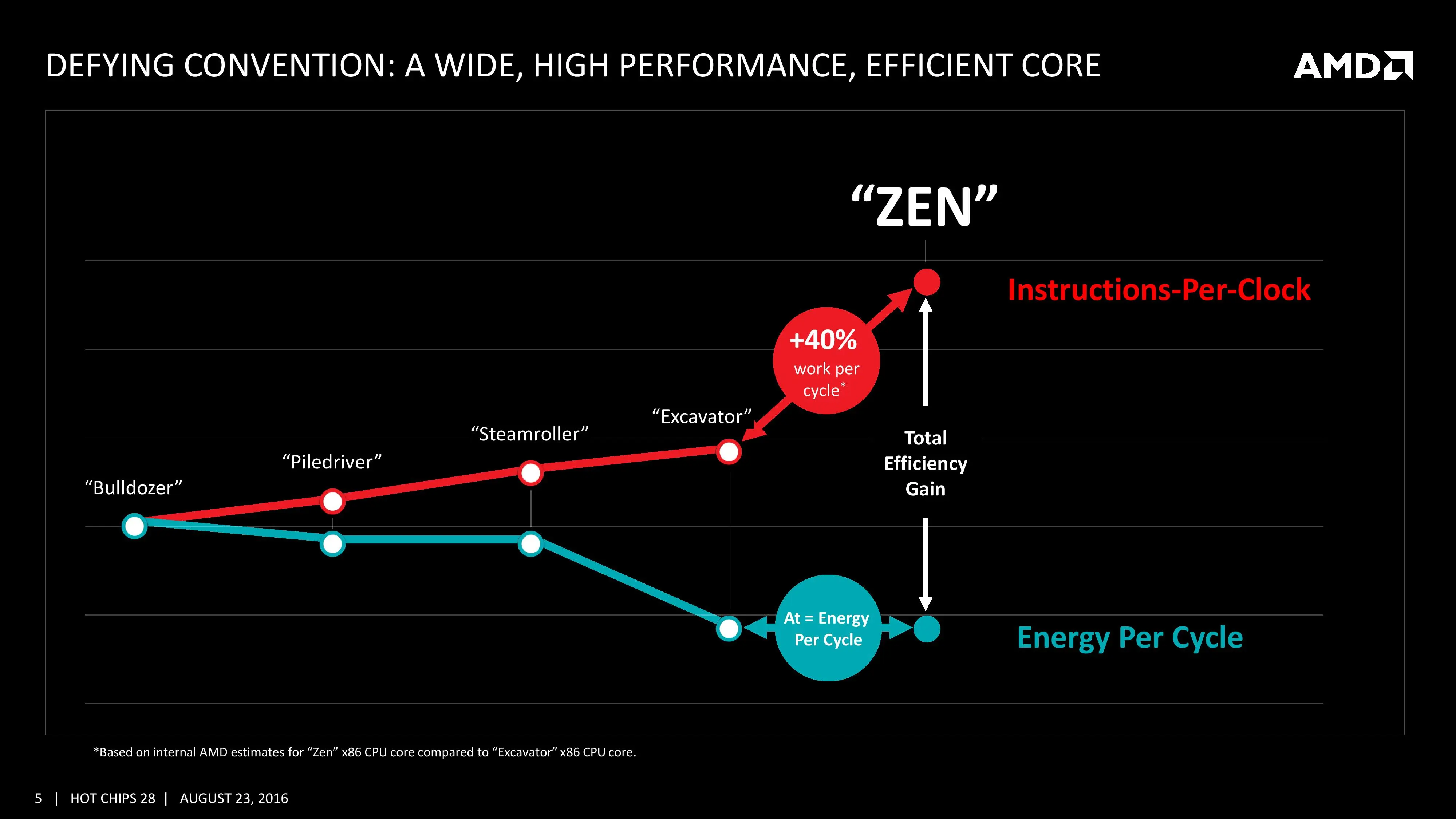
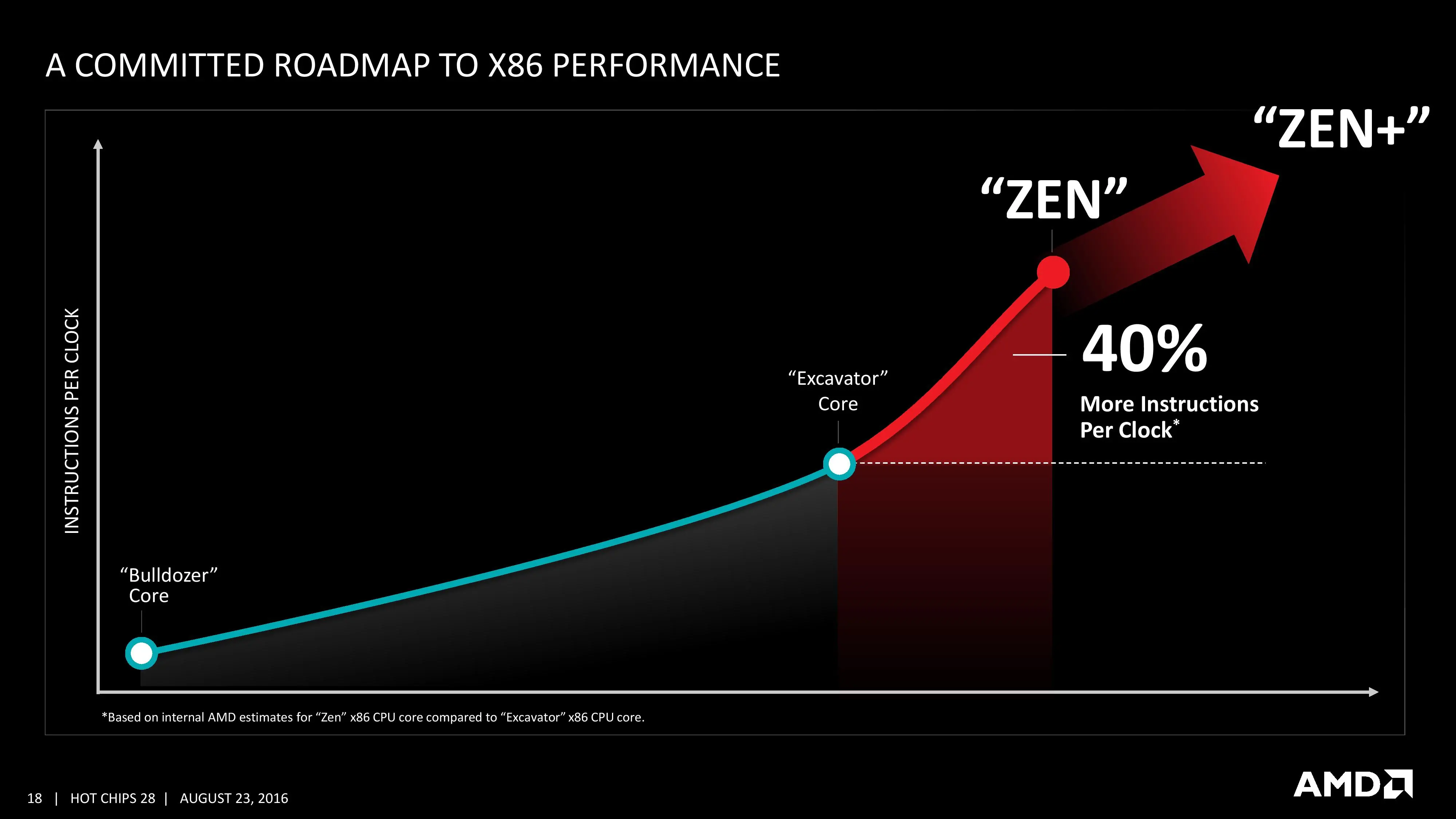
No ha dado detalles muy específicos y jugosos como las frecuencias que alcanzarán los procesadores o las latencias de las cachés utilizadas, pero sí han comentado bastante sobre cómo funciona internamente las distintas unidades del procesador. La mejora del 40 % de rendimiento sobre Excavator procede sobre todo de la mejora en las cachés (y sus latencias) y el nuevo motor del núcleo Zen, bastante más complejo.
A diferencia de generaciones anteriores, Zen está diseñado para ser utilizado tanto en sistemas de bajo consumo y portátiles (Jaguar) como de alto rendimiento (Excavator). El núcleo de la arquitectura Zen es el complejo de CPU (CCX), que está compuesto por cuatro núcleos con acceso a 2 MB de caché L3 y 512 KB de caché L2 específica de cada núcleo. La caché L3 de cualquier núcleo puede ser accedido por los demás por lo que en la práctica son 8 MB de caché L3 común a todos, y sobre todo es usada como respaldo de la caché L2.
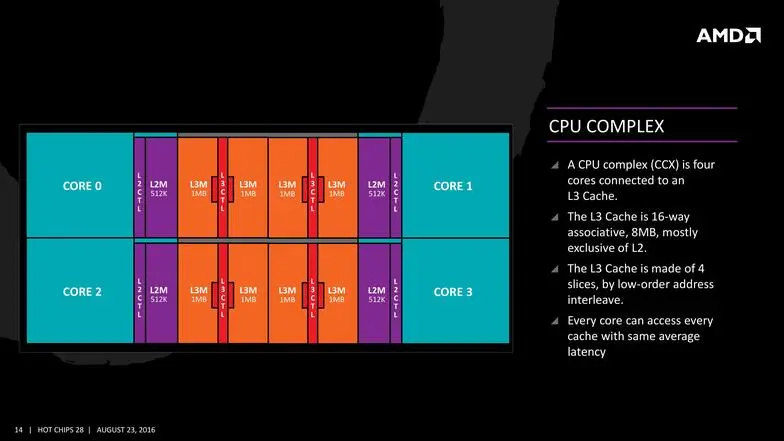
Un CCX se puede combinar con otros a través de una interconexión de datos intermedia, por lo que no estarán conectados directamente. Por tanto en el procesador de ocho núcleos a competir con el i7-6950X hay dos CCX interconectados. En general lo comentado por AMD apunta a lo mismo de que el CCX incluye mejoras en el motor de los núcleos, con mejoras en el predictor de saltos, mayor caché de operaciones, mayor ancho de instrucciones, y gestores de instrucciones.
Un programa se traduce en diversas instrucciones entendibles por los procesadores, y la intención de AMD con los cambios es que se pueda ver un mayor número de instrucciones a ejecutar de manera anticipada. De esta forma se pueden realizar preparaciones previas de las colas de instrucciones así como optimizaciones en su ejecución, como fusionar varias instrucciones en una única microoperación (operaciones en que se descompone una instrucción de mayor ámbito).
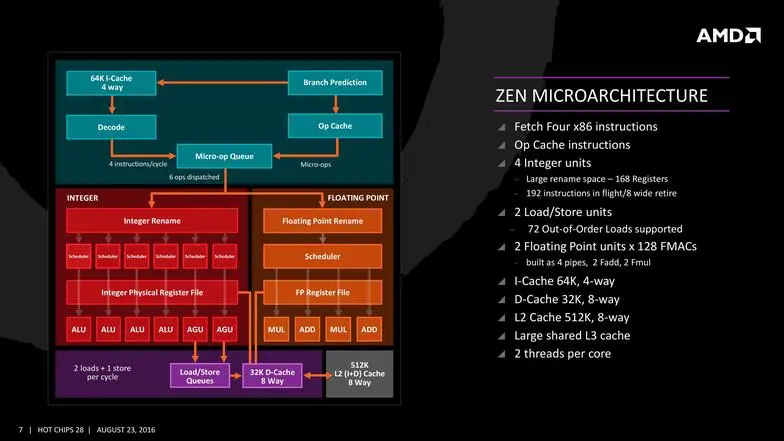
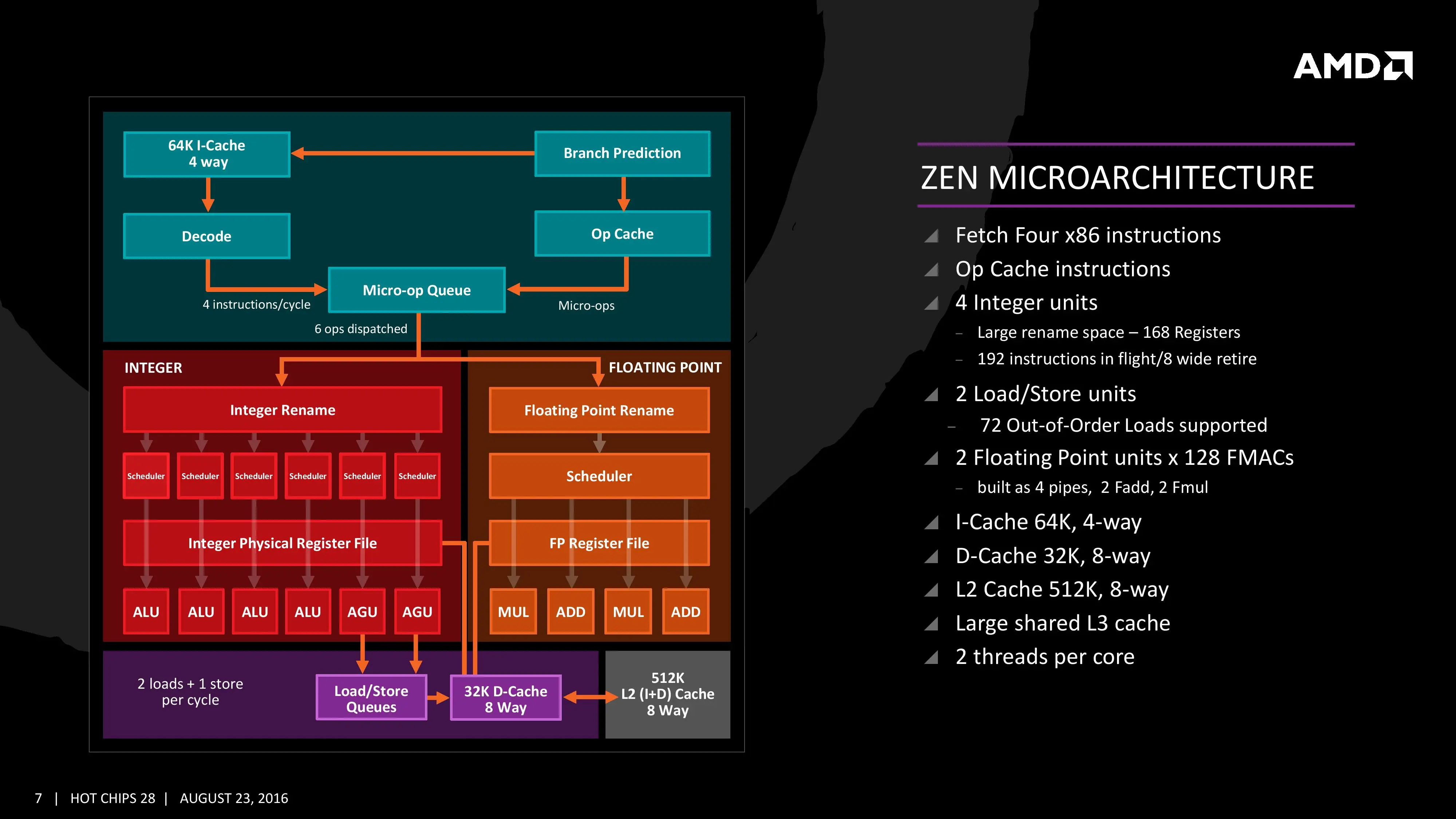
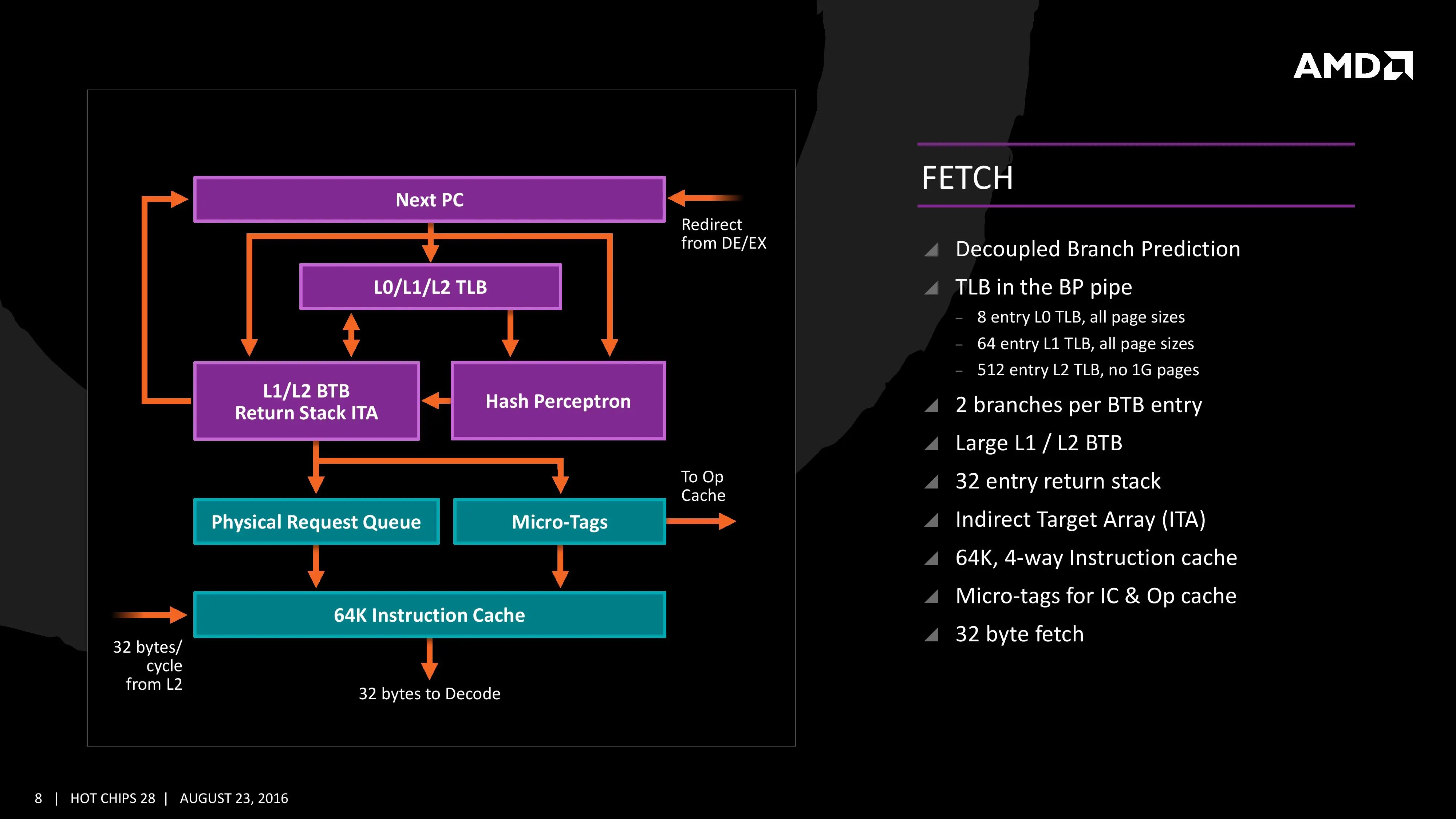
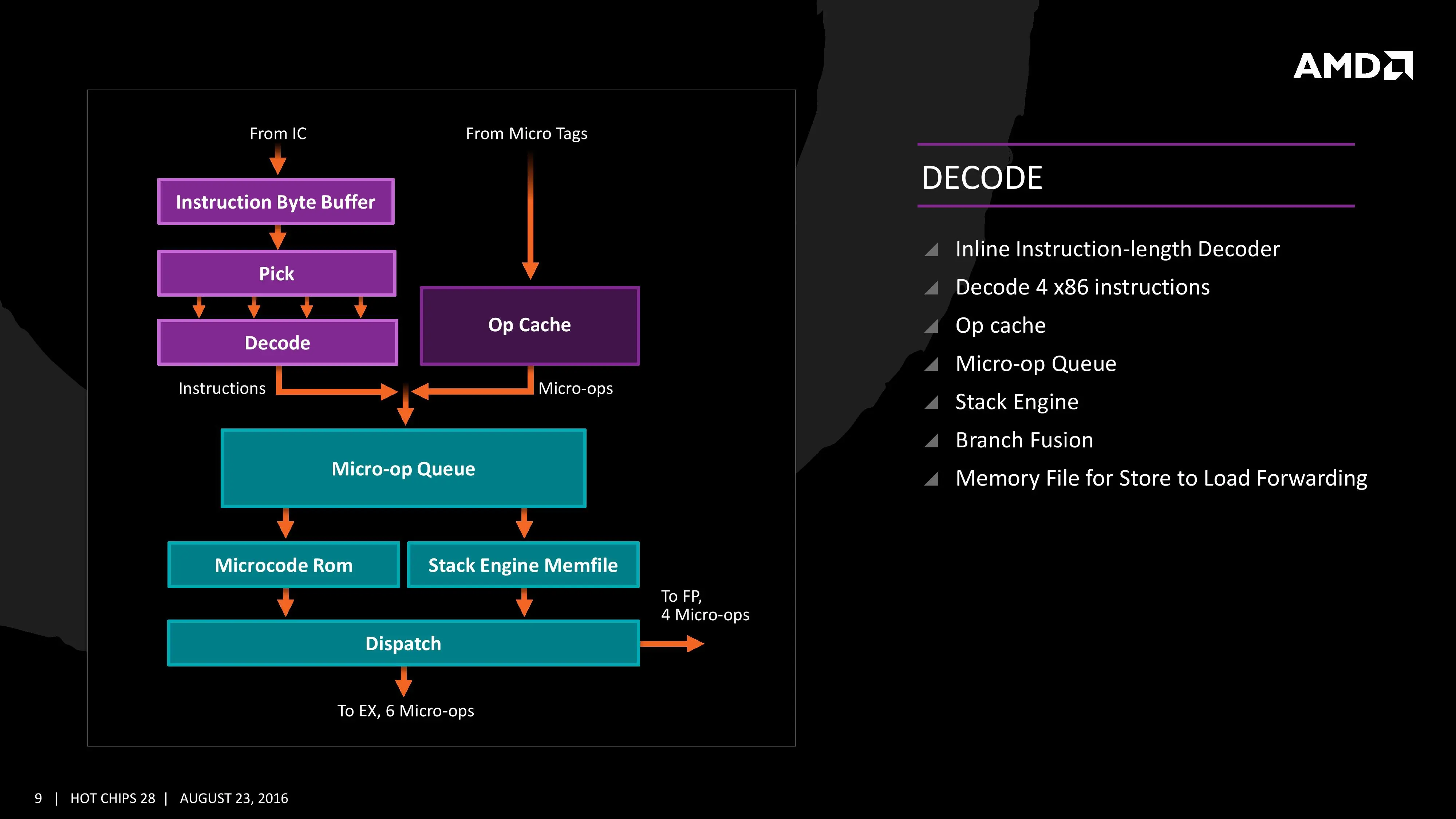
La transparencia anterior es de un núcleo Zen, con un decodificador de cuatro instrucciones por ciclo capaz de transformarlo en seis operaciones a ejecutar por ciclo. Se ha mejorado el búfer de instrucciones para su ejecución fuera de orden hasta 72. Con la intención de poder maximizar el nivel de uso del procesador, el predictor de saltos (predecir a qué parte del código se tiene que saltar con antelación) se ha desacoplado. En última instancia el objetivo es mejorar la ejecución paralela del procesador.
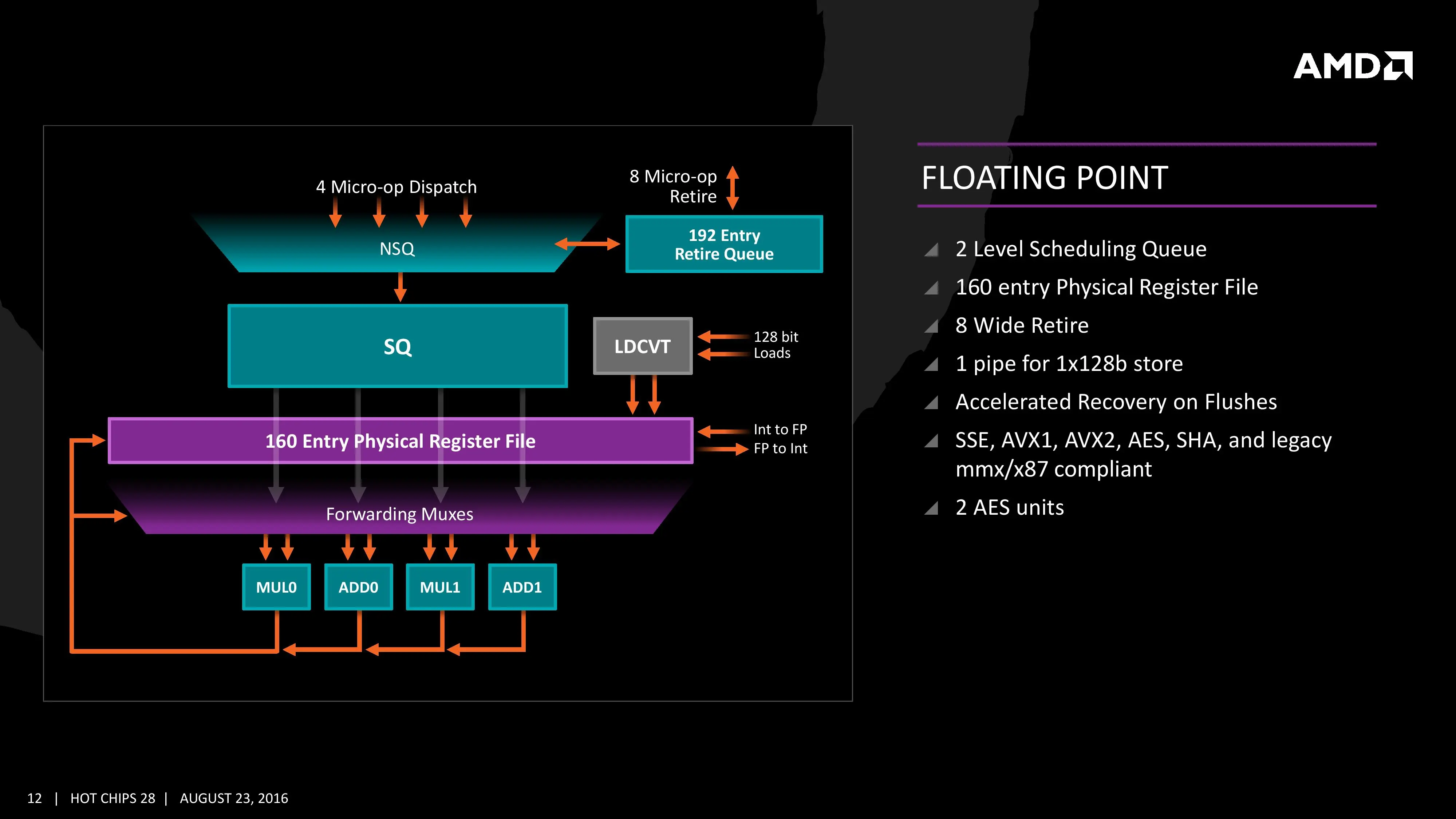
Siguiendo con el decodificador, es capaz de mandar cuatro instrucciones al planificador de operaciones en coma flotante, o seis al planificador de operaciones con enteros, o una mezcla, enviándolas a uno u otro planificador de manera simultánea. También hay diversas optimizaciones para evitar la duplicidad de información en caché, siempre con la intención de minimizar el consumo del chip en acciones innecesarias. Se han añadido medidas para mejorar la previsión de cuándo se va a producir un fallo de caché (que se vaya a acceder en algún momento a datos que no están en caché, por lo que se pueden traer anticipadamente).
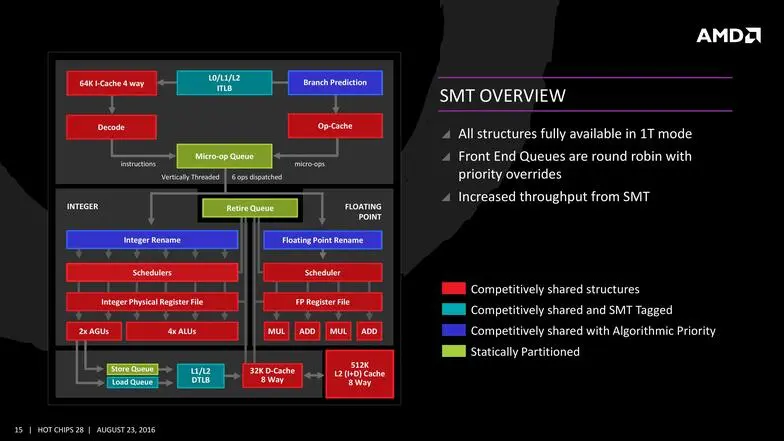
En la práctica, AMD apunta a que el ancho de banda de las cachés de nivel 1 y 2 (L1, L2) se ha duplicado con respecto a Excavator, por lo que está en mucha mejor posición para plantar cara a Intel en un terreno que conocen muy bien. Muy necesario a la hora de mover información hacia los núcleos, y por lo que AMD tampoco ha querido hablar mucho sobre las latencias de estas nuevas cachés empleadas.
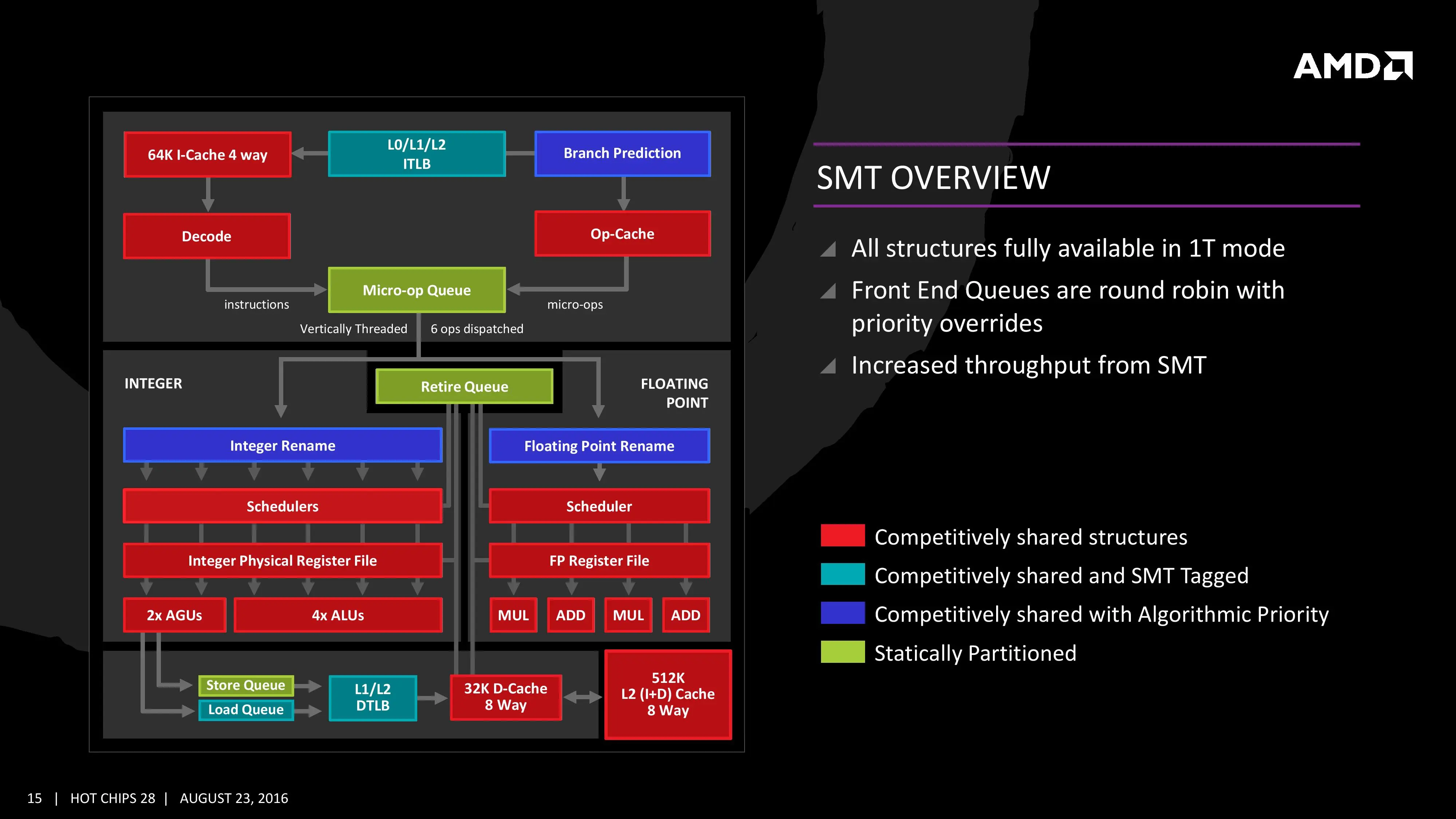
Pero sobre todo las mejoras en computación van a proceder a que la arquitectura tiene soporte a la multiejecución simultánea (SMT), o ejecución de varios hilos distintos al mismo tiempo. Los hilos se podrán promocionar a mayores prioridades en cualquier momento, o sacarlos de ejecución sin penalizar al procesador, y competirán por los recursos del CCX.
AMD también ha añadido instrucciones nuevas que podrán ser utilizadas por los compiladores para optimizar la ejecución de instrucciones (incluida la coalescencia de PTE para transformar varias páginas de tamaño 4 KB en una página de 32 KB y mejorar la eficiencia, o CLZERO para limpiar una línea de caché en un único paso), pero se incluyen nuevas instrucciones de criptografía y orientadas específicamente a la computación de alto rendimiento (HPC).
Lo que se puede asegurar a primera vista es que AMD va a crear procesadores capaces de competir con los actuales modelos de Intel, en igualdad de condiciones. Como ha comentado el jefe de arquitectura de AMD en el webcast, sus ingenieros están pensando continuamente en nuevas formas de mejorar esta arquitectura adaptando nuevas características, y eso desembocará en Zen+, que es la segunda generación de Zen que la compañía ya tiene en su hoja de ruta. A medida que se acerque 2017 irán dando más información a alto nivel de los procesadores que están por llegar.









Fuente: Presentación en PDF, Webcast. Vía: AnandTech.



