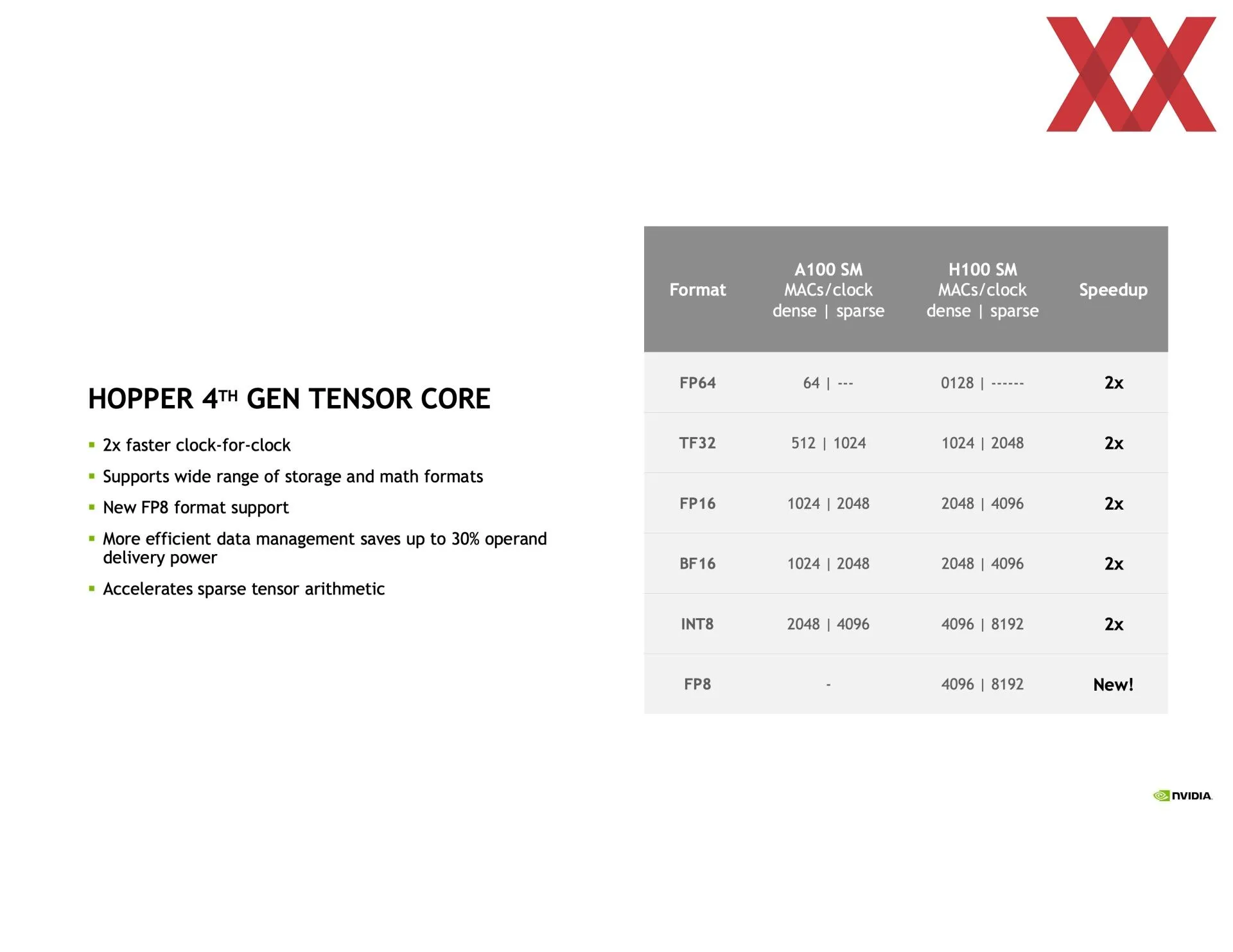
NVIDIA sigue hablando de sus últimos productos de computación en el Hot Chip 34, y le ha tocado el turno a la unidad gráfica GH100 integrada en su aceleradora H100. Es de arquitectura Hopper orientada netamente a cómputo, por lo que carece de la parte de los núcleos de trazado de rayos pero mantiene los indispensables hoy en día núcleos tensoriales. Con alguna novedad, como la inclusión de cálculo en FP8 (coma flotante de ocho bits) en estos últimos núcleos.
-
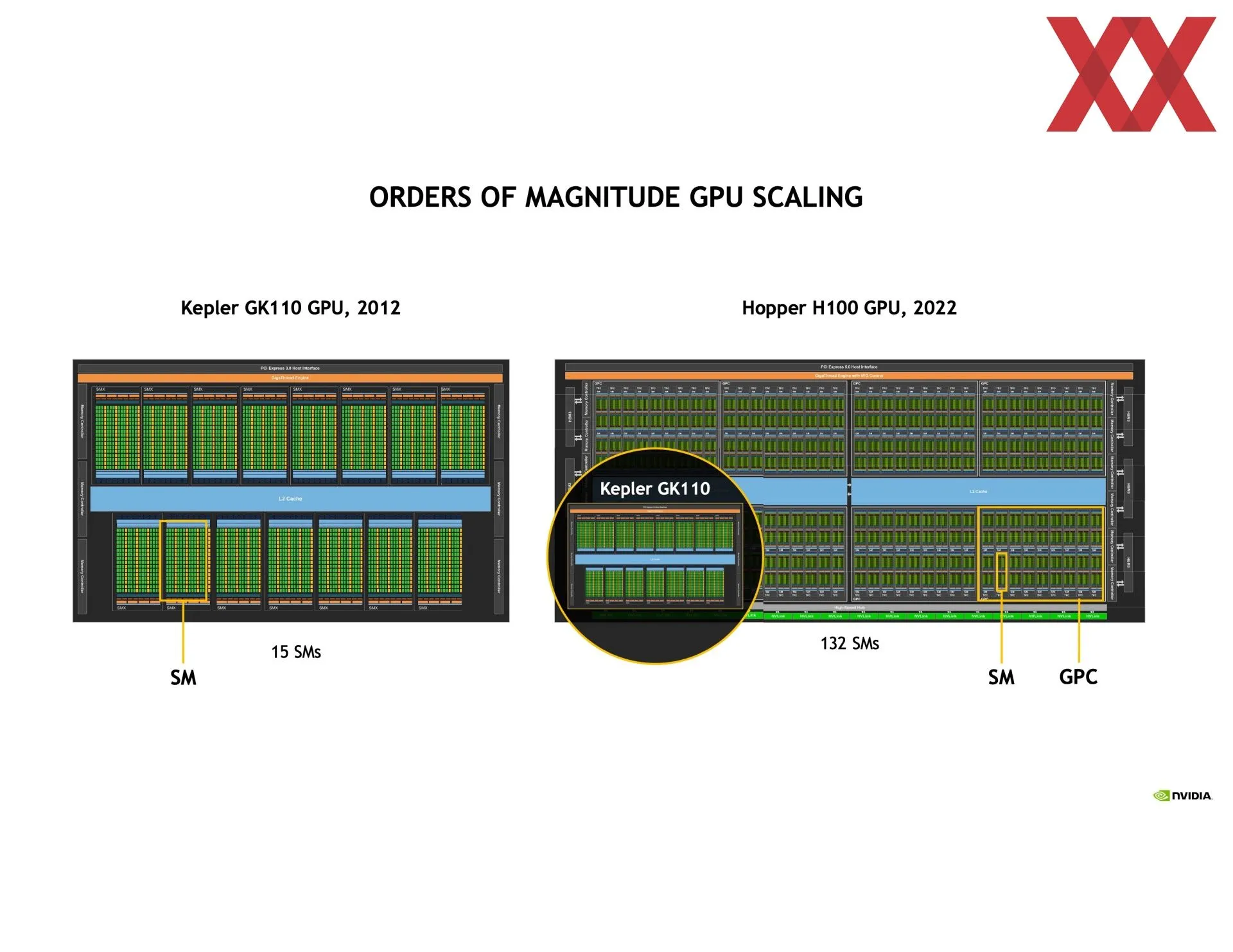
NVIDIA anuncia la arquitectura Hopper con el GH100 de 814 mm^2 a 4 nm, y la H100 de 16 896 CUDA y 80 GB HBM3
22 mar 2022 0
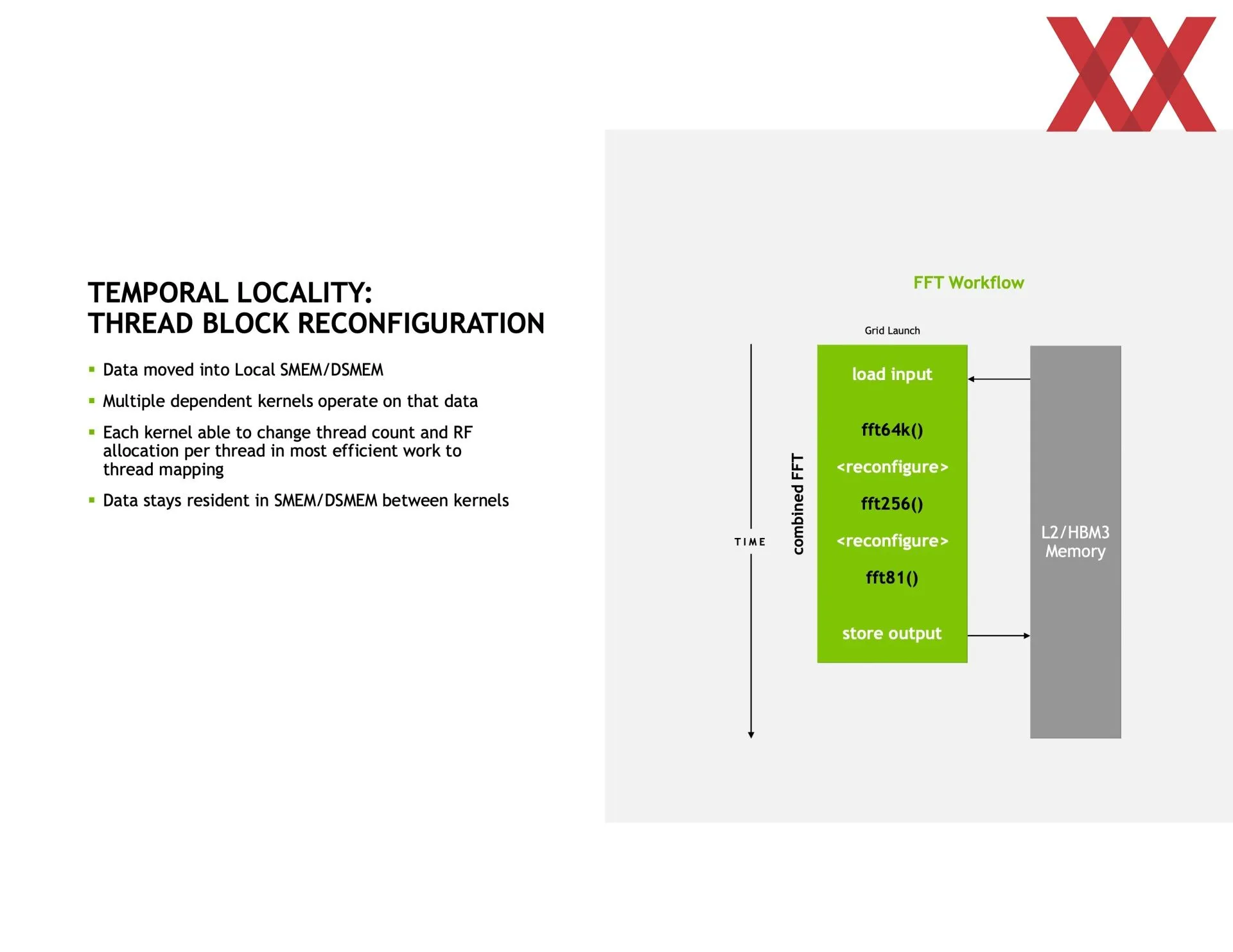
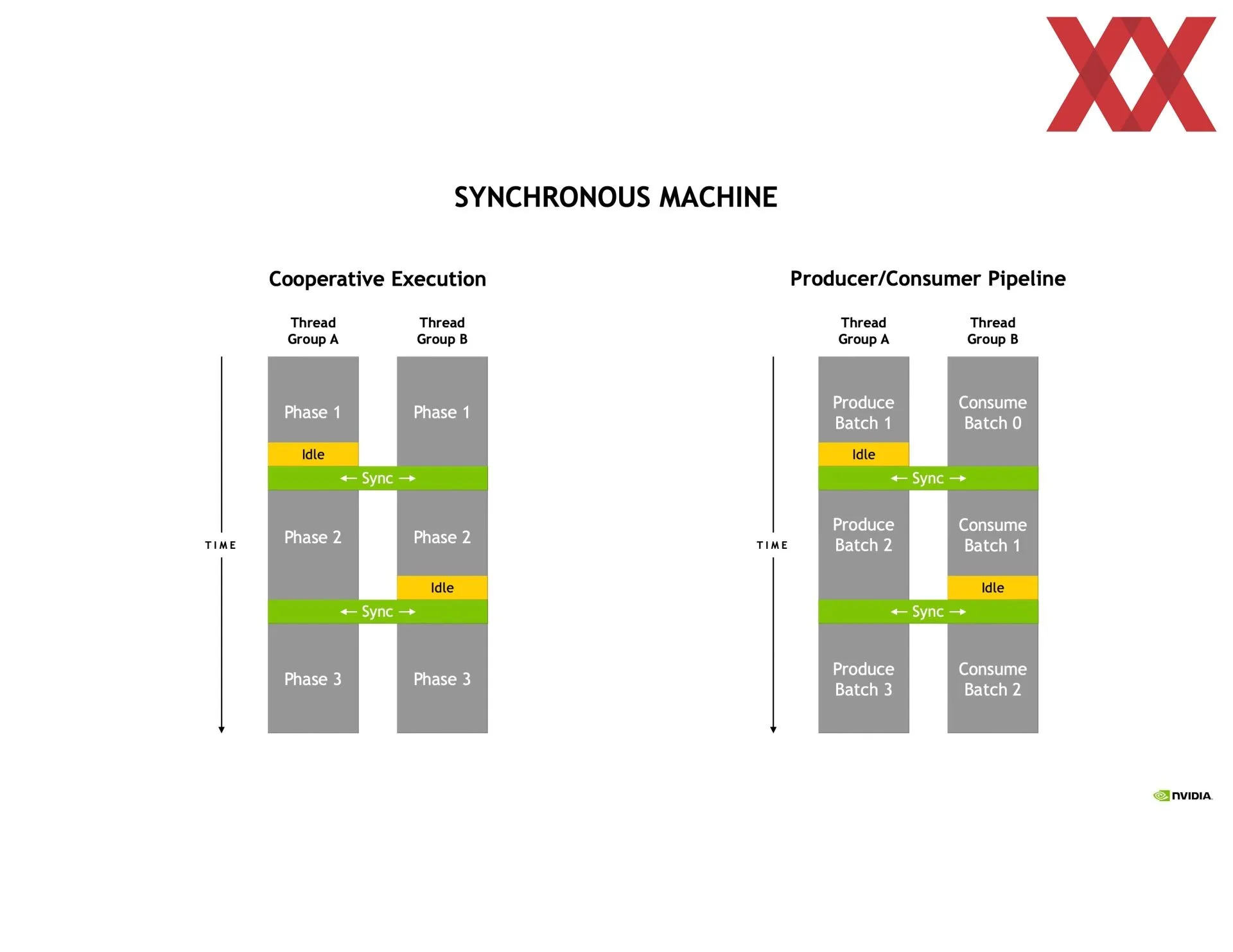
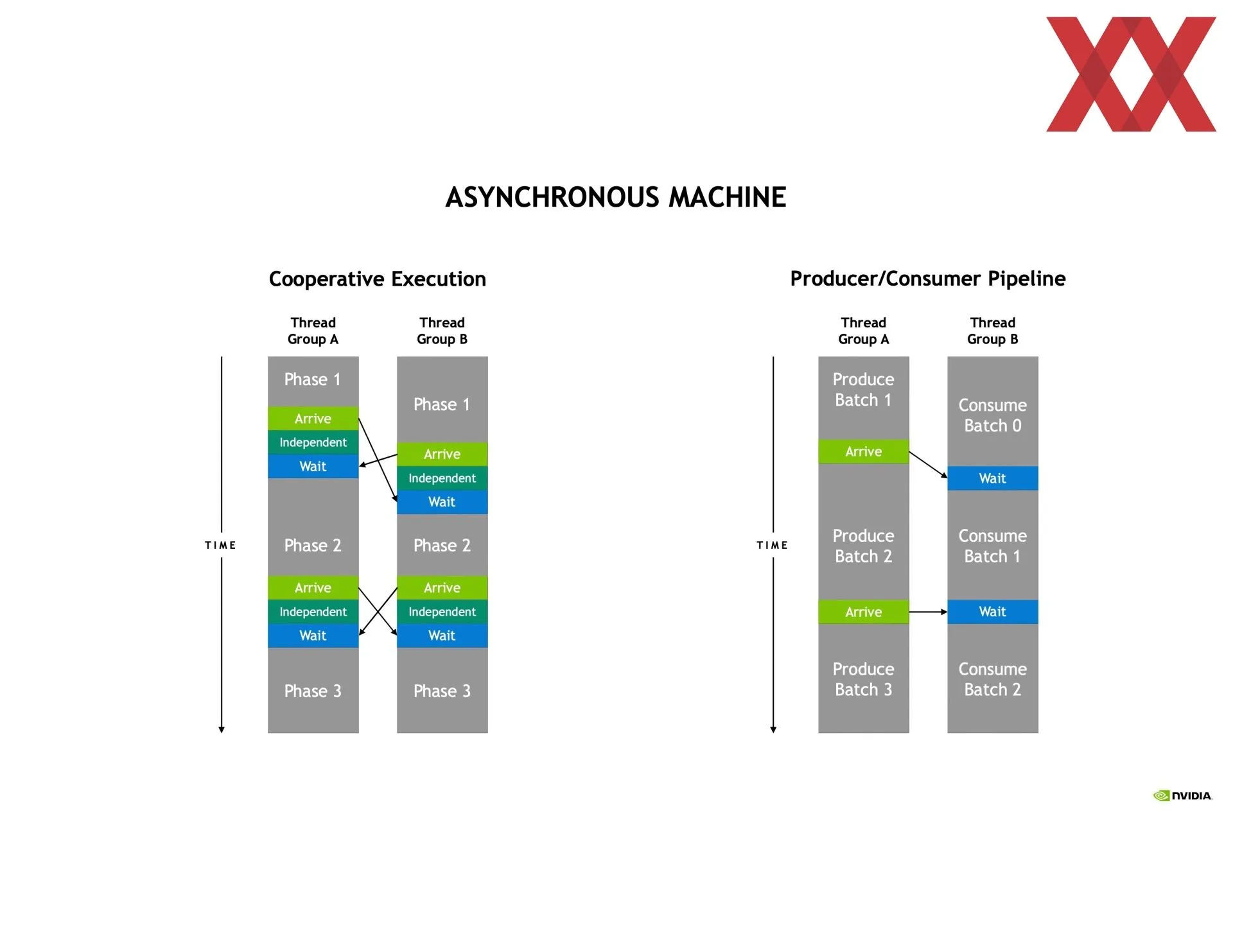
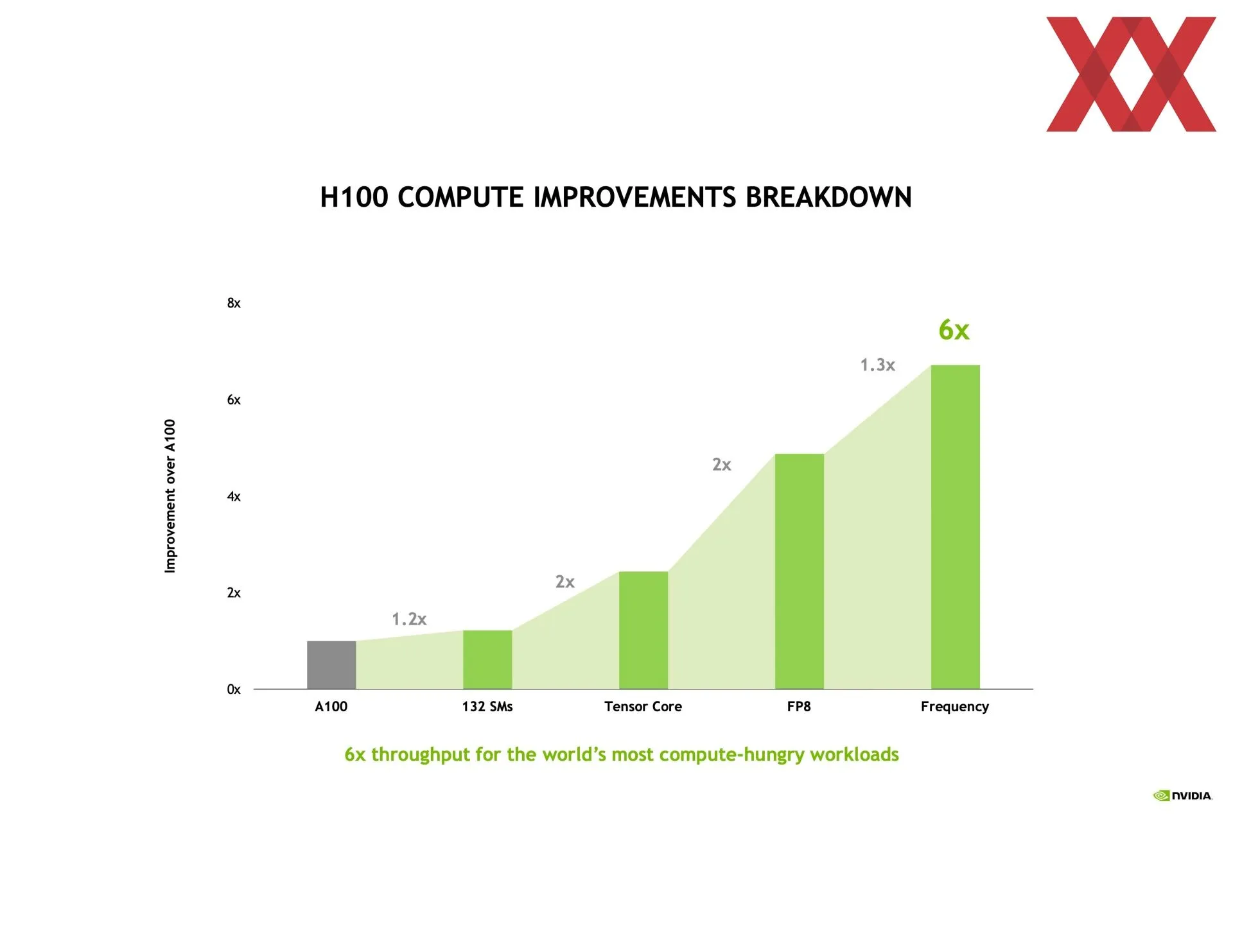
Las generalidades están recogidas en el libro blanco de la arquitectura Hopper publicado hace unos meses por NVIDIA. Las particularidades de las que se puede hablar se van detallando en diversas charlas como las del Hot Chips. En este caso ha hablado más sobre las mejoras en la ejecución asíncrona de la arquitectura Hopper que obviamente beneficia a la potencia en computación. Desde el principio NVIDIA ha calificado a esta arquitectura como la primera GPU verdaderamente asíncrona.
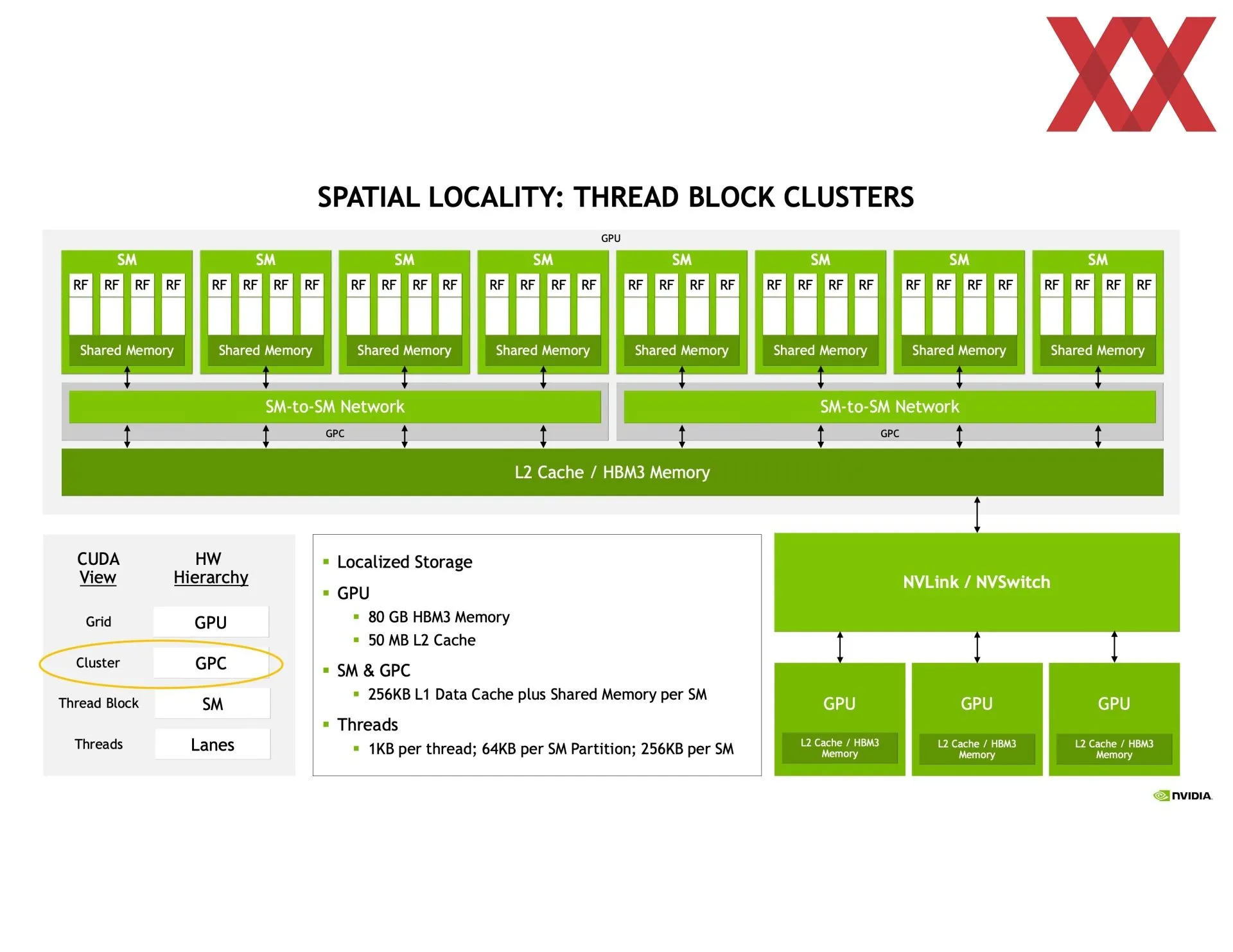
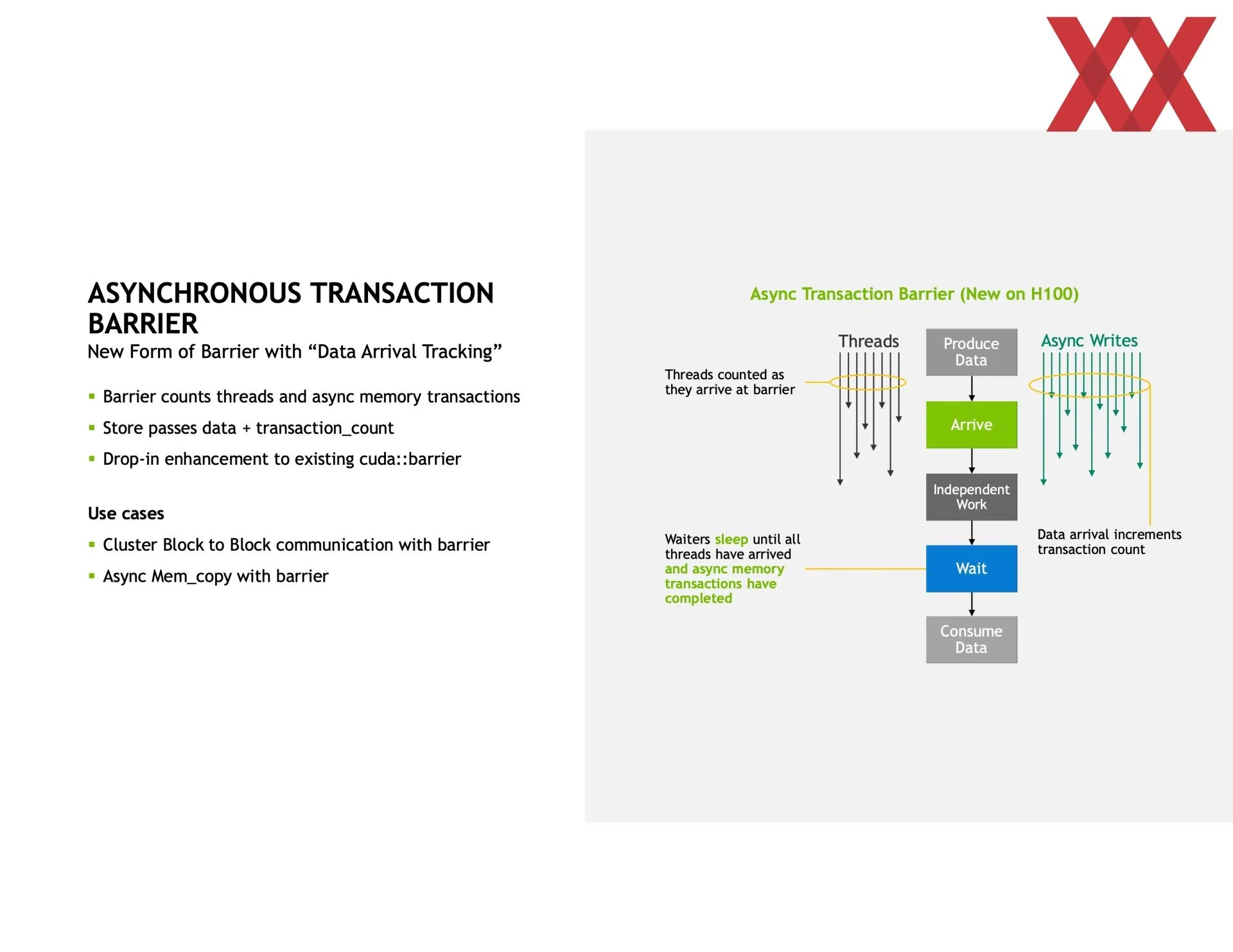
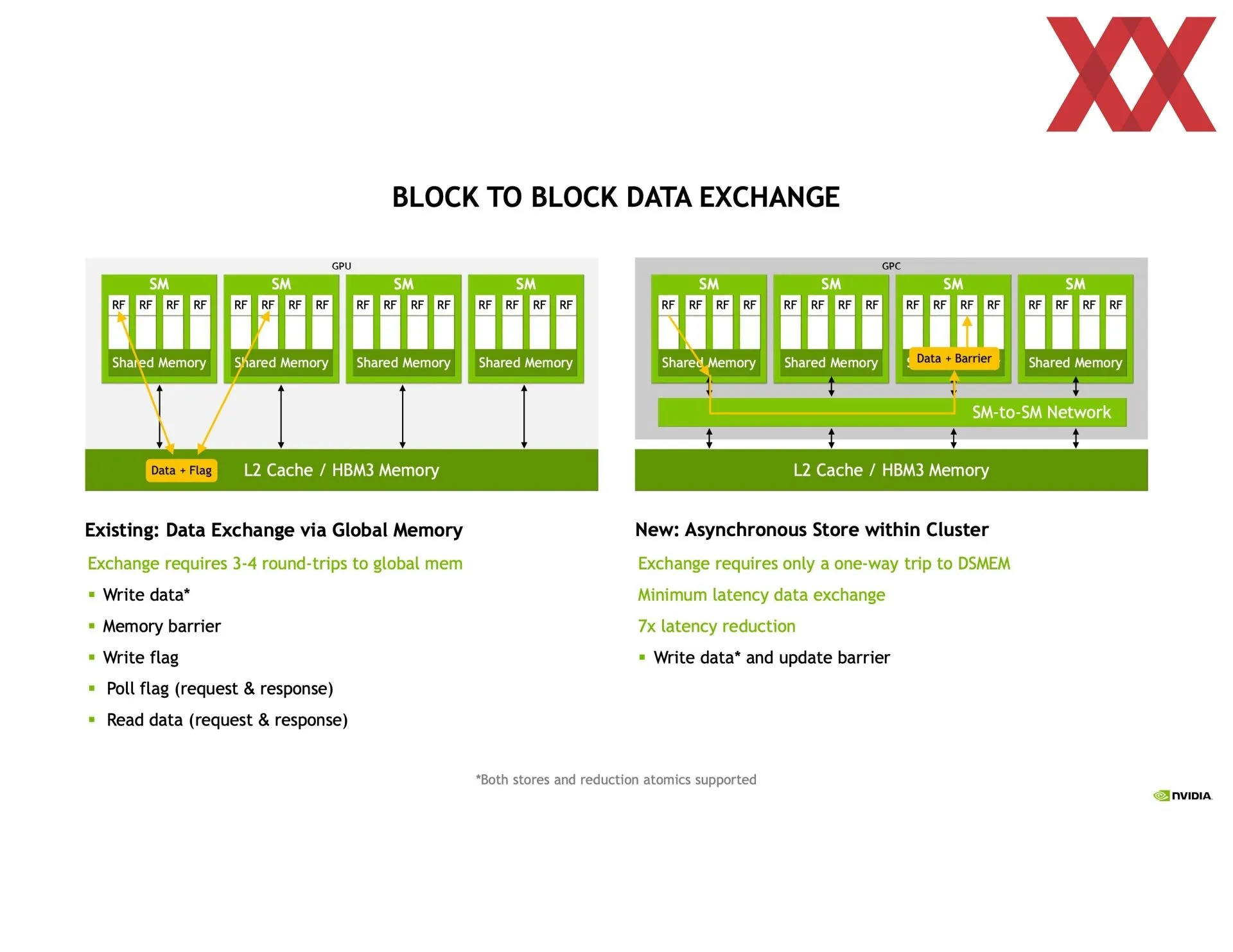
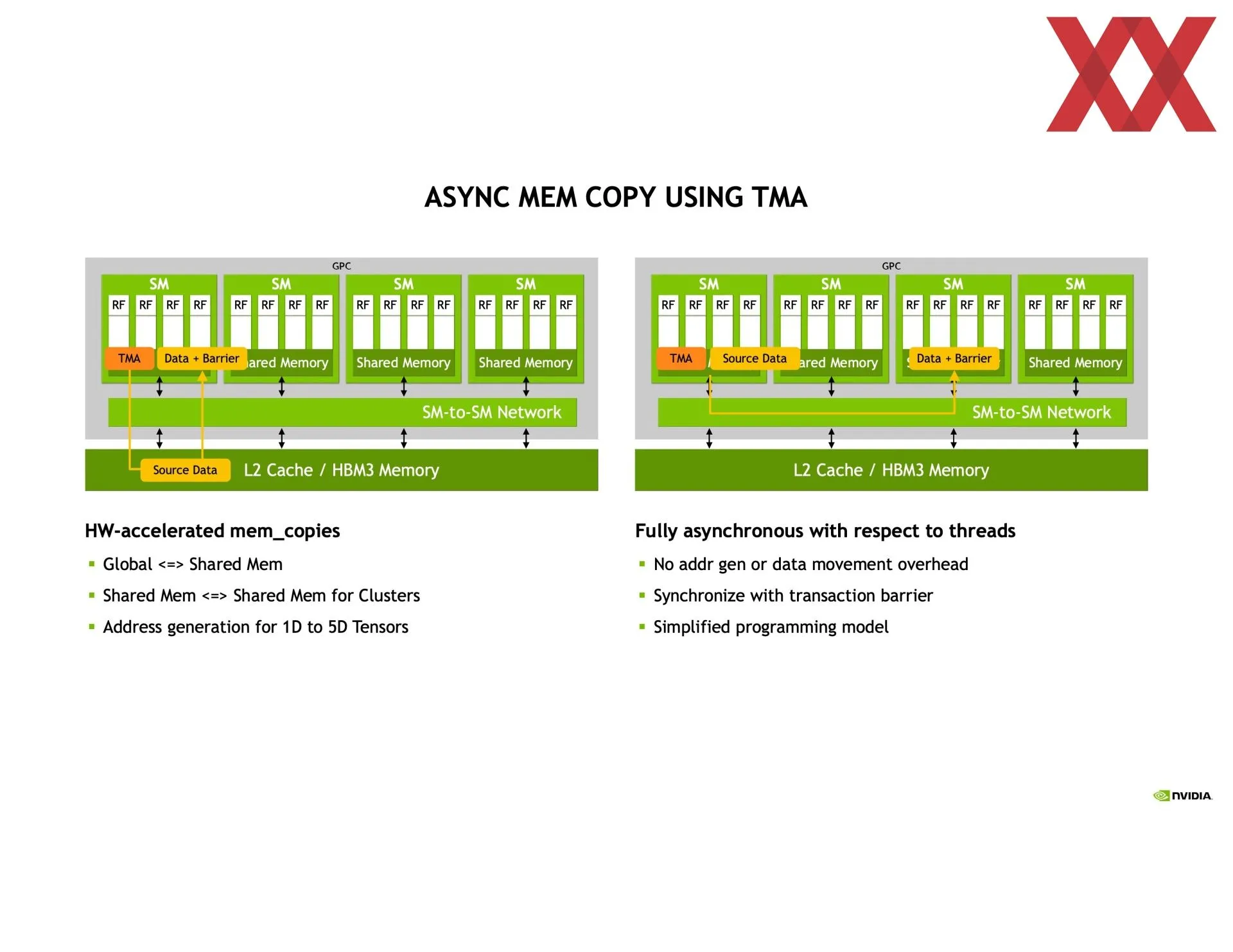
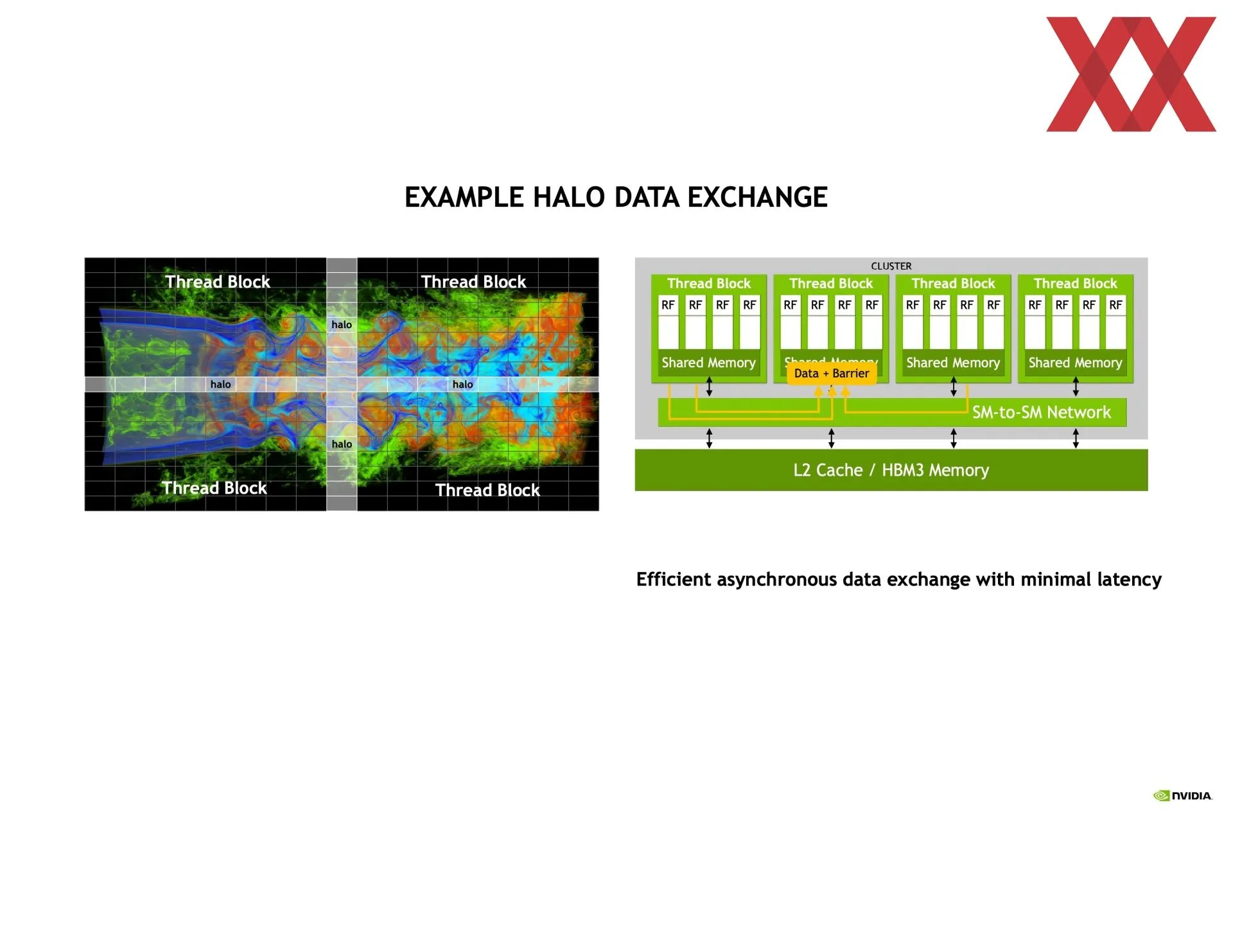
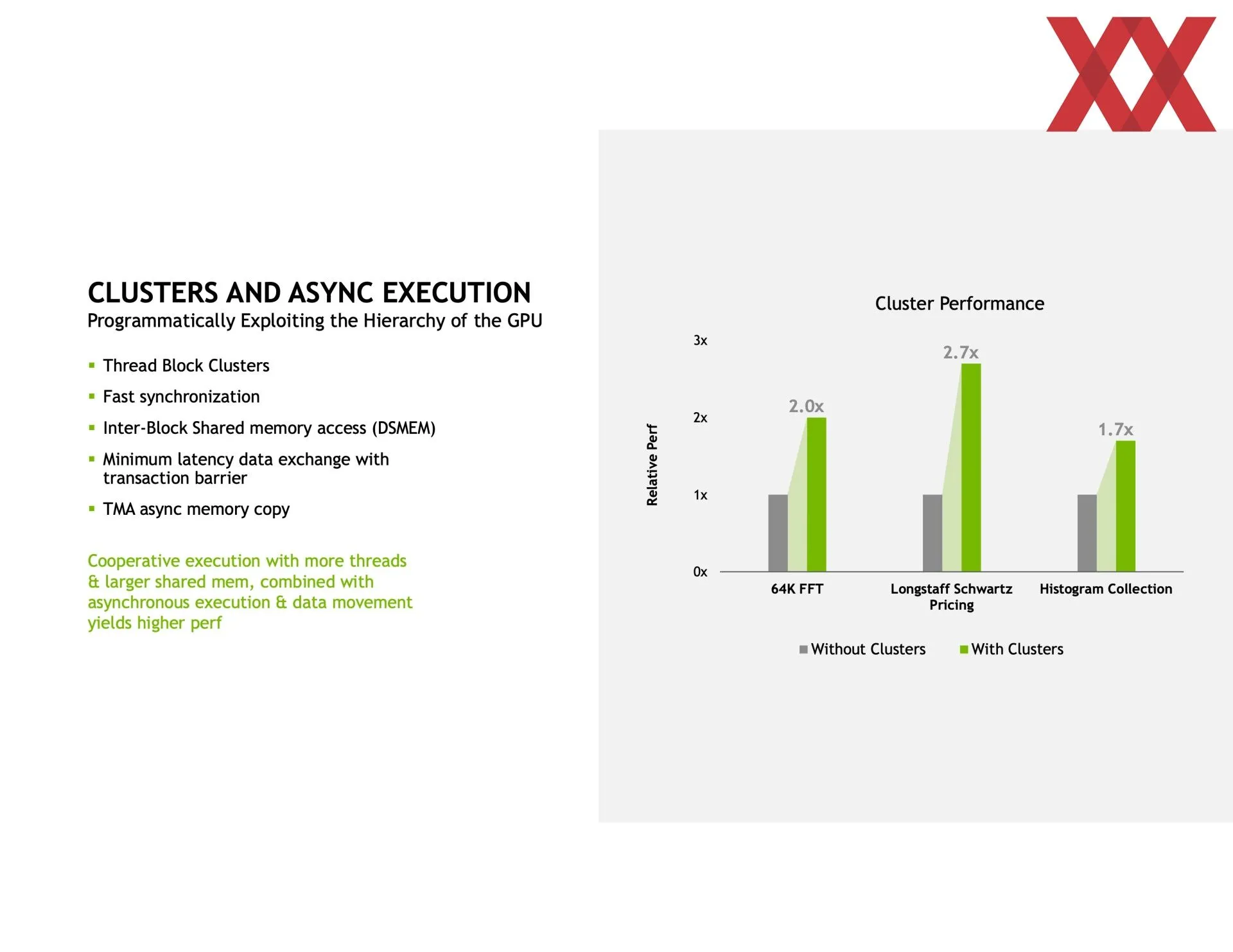
En las trasparencias compartidas se puede ver que va en la dirección de detallarlo más que en el libro blanco, y eso que es el tema principal de la arquitectura. Empieza hablando de la mejora de la comunicación entre los SM (multiprocesadores de flujos de datos), de las que el chip GH100 tiene 144 agrupadas en ocho GPC (clústeres de procesamiento de GPU). Dentro de cada GPC se pueden crear clústeres de dos o más SM entre los cuales se podrá compartir información de manera directa y totalmente asíncrona a la vez que se les asignará un bloque de hilos de manera concurrente.
Eso implica que una SM puede acceder directamente a la caché de otra SM, reduciendo por tanto tiempos en copia de memoria o los de tener que buscar la información en la memoria principal, entre otros. O sea, la latencia en general, además de que amplía la caché disponible. Todo esto se tiene que programar usando CUDA, por lo que no es nada automático, aunque las ganancias de rendimiento son más que significativas. Dependiendo de lo que se haga se puede ganar hasta un 170 % más de rendimiento creando los clústeres de SM.
Es posible que estos cambios puedan llegar a la arquitectura Ada de las RTX 40, pero para aprovecharlas habría que implementarlos en los motores gráficos. Así que toda ganancia de rendimiento llevaría años en tener un efecto práctico en los juegos. Por un lado, es posible que la mejora real de rendimiento inicialmente de las RTX 40 sea menor de lo esperado, pero que con el tiempo sea bastante mucho mejor.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}