
AMD ha presentado su primer modelo de lenguaje grande (LLM) completamente abierto, denominado OLMo, con 1000 millones de parámetros. Está disponible en GitHub. Este modelo ha sido entrenado internamente por AMD utilizando una amplia cantidad de conjuntos de datos, los cuales se indica en el proyecto, y está diseñado para aplicaciones que requieran capacidades avanzadas de razonamiento e interpretación de instrucciones.
OLMo fue entrenado en un conjunto de datos de 1.3 billones de tókenes, empleando 16 nodos, cada uno equipado con cuatro aceleradoras Instinct MI250, sumando un total de 64 procesadores. El proceso de entrenamiento se llevó a cabo en tres etapas:
- OLMo 1B: modelo preentrenado en un subconjunto de Dolma v1.7, centrado en la predicción del siguiente token para capturar patrones lingüísticos y conocimientos generales.
- OLMo 1B SFT: modelo afinado supervisadamente en dos fases, utilizando los conjuntos de datos Tulu v2, OpenHermes-2.5, WebInstructSub y Code-Feedback, mejorando su capacidad para seguir instrucciones y su rendimiento en tareas relacionadas con ciencia, programación y matemáticas.
- OLMo 1B SFT DPO: modelo alineado con las preferencias humanas mediante la Optimización Directa de Preferencias (DPO) utilizando el conjunto de datos UltraFeedback, priorizando respuestas que reflejan retroalimentación humana típica.
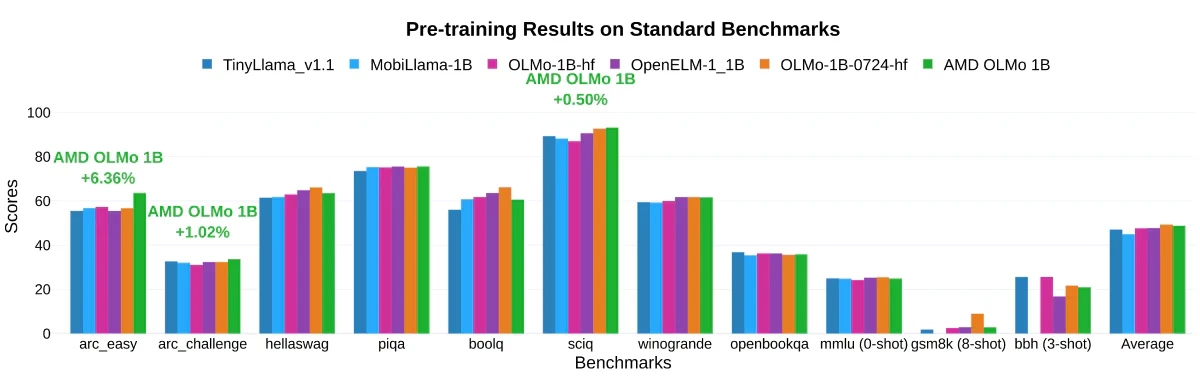
En pruebas internas, OLMo ha demostrado un rendimiento notable en comparación con otros modelos de código abierto de tamaño similar, como TinyLlama-1.1B, MobiLlama-1B y OpenELM-1_1B, en evaluaciones estándar de razonamiento general y comprensión multimodal. Específicamente, el modelo SFT mostró mejoras significativas de precisión, con incrementos del 5.09 % en MMLU y del 15.32 % en GSM8k. OLMo se puede utilizar en las NPU de sus procesadores como la de los Ryzen AI 300.
Vía: Tom's Hardware.



