
Nvidia ha anunciado finalmente su nueva arquitectura gráfica, tras pasar dos años desde que presentara la Turing con trazado de rayos y núcleos tensoriales. Esta arquitectura se llama Ampère, y Nvidia ha confirmado que será la misma para las tarjetas gráficas generalistas GeForce, si bien inicialmente la ha presentado para el chip gráfico de la nueva tarjeta de cómputo A100.
El proceso litográfico de fabricación elegido para el chip A100 que utiliza es el de 7 nm de TSMC, y eso significa que en comparación con el GV100 de la Tesla V100 predecesora permite casi triplicar el número de transistores en un tamaño ligeramente superior. Eso son 826 mm2 frente a 815 mm2 y 54 000 millones de transistores frente a 21 100 M.
Esta nueva A100 cuenta con 6912 núcleos CUDA frente a los 5120 de la Tesla V100, funcionando a un turbo de unos 1.41 GHz, y aumenta significativamente la potencia de la tarjeta, aunque no tanto en procesamiento general sino en el cálculo de tensores. Un tensor es una estructura algebraica usada en inteligencia artificial, y por tanto una tarjeta gráfica para cómputo tiene que destacar en este terreno.
| Comparativa de aceleradoras de cómputo de Nvidia | |||||
| A100 | Tesla V100 | Tesla P100 | |||
| Núcleos CUDA FP32 | 6912 | 5120 | 3584 | ||
| Frec. turbo | ≈1410 MHz | 1530 MHz | 1480 MHz | ||
| Reloj memoria | HBM2 2.4 Gb/s | HBM2 1.75 Gb/s | HBM2 1.4 Gb/s | ||
| Bus memoria | 5120 bits | 4096 bits | 4096 bits | ||
| Ancho de banda memoria | 1.6 TB/s | 900 GB/s | 720 GB/s | ||
| VRAM | 40 GB | 16/32 GB | 16 GB | ||
| Precisión simple | 19.5 TFLOPs | 15.7 TFLOPs | 10.6 TFLOPs | ||
| Doble precisión | 9.7 TFLOPs | 7.8 TFLOPs | 5.3 TFLOPs | ||
| Tensor INT8 | 624 TOPs | N/A | N/A | ||
| Tensor FP16 | 312 TFLOPs | 125 TFLOPs | N/A | ||
| Tensor TF32 | 156 TFLOPs | N/A | N/A | ||
| Interconexión | NVLink 3 12 enlaces a 600 GB/s | NVLink 2 6 enlace a 300 GB/s | NVLink 1 4 enlaces a 160 GB/s | ||
| GPU | A100 (826 mm2) | GV100 (815 mm2) | GP100 (610 mm2) | ||
| Transistores | 54 200 M | 21 100 M | 15 300 M | ||
| Consumo | 400 W | 300/350 W | 300 W | ||
| Litografía | TSMC 7 nm | TSMC 12 nm FFN | TSMC 16 nm FinFET | ||
| Interfaz | SXM4 | SXM2/SXM3 | SXM | ||
| Arquitectura | Ampère | Volta | Pascal | ||
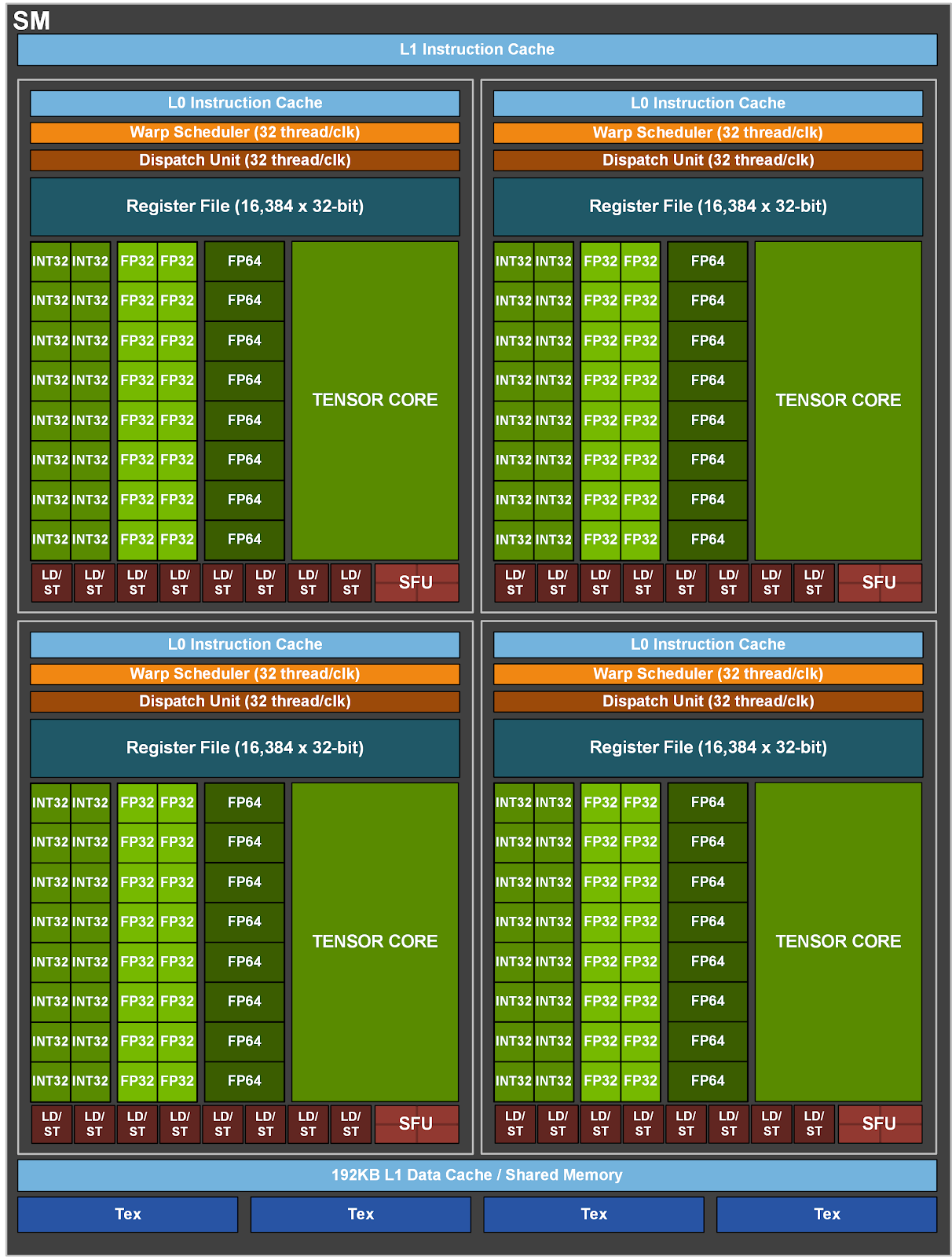
Por ello, la mejora de la arquitectura y de los núcleos tensoriales de la arquitectura Ampère hace que el cálculo de tensores en FP16 pase de 125 TFLOPS a los 312 TFLOPS, y se permite el cálculo de tensores en TF32 e INT8. Ambos son cálculos normales en inteligencia artificial pero que no todas las arquitecturas los implementan por hardware. En INT8 la potencia de cómputo pasa a los 624 TOPS, y en TF32 se obtiene 156 TOPS.
También destaca que a pesar de casi triplicar el número de transistores —bueno, las multiplica por 2.6 para ser más correcto, si bien este chip no está totalmente desbloqueado por lo que parte de esos transistores no se usan; lo explico más abajo— el consumo apenas sube 50 W, lo que hace que esta tarjeta pase de un consumo de 350 W hasta los 400 W, teniendo en cuenta que el chip GV100 estaba producido con el proceso de 12 nm de TSMC. En todos los parámetros básicos esta tarjeta gráfica es muy superior a su predecesora.

El tema está en que las distintas optimizaciones de la arquitectura, la potencia en entrenamiento de redes neuronales se multiplica por seis respecto a la Tesla V100, y en inferencias se multiplica por siete. En potencia de cómputo más generalista se queda más bien en el doble de rendimiento, por esas optimizaciones para programas, aunque en potencia de cómputo en bruto apenas arroje un 33 % más. Pero no es una tarjeta gráfica para tareas de cómputo generalistas, sino para inteligencia artificial.
Destaca en ello el uso de memoria HBM2 a 2.43 GHz, con un total de 40 GB de VRAM, con un bus de 5192 bits —cinco chips HBM2 a 1024 bits cada uno— lo que arroja un impresionante ancho de banda de 1.6 TB/s. La compañía ha indicado que incluye 432 núcleos tensoriales de tercera generación, a razón de cuatro por multiprocesador de flujos de datos (SM).

La tarjeta usa una interfaz PCIe 4.0, y usa un conector especial de comunicación NVLink 3 de doce enlaces lo que aporta una comunicación intertarjetas de 600 GB/s, que es muy superior a los 31.5 GB/s de la comunicación PCIe 4.0 estándar, y es necesaria para las máquinas en las que se pueden poner en paralelo hasta ocho tarjetas A100 como las de la imagen de cabecera.
Hay un dato de interés sobre este chip y es que parte de él está desactivado. El chip GA100 completo, según indica Nvidia, incluye 8192 núcleos CUDA con seis controladores de memoria HBM2 (bus máximos de 6144 bits para unos 1.92 TB/s), lo que abre la puerta a que Nvidia anuncie en un futuro, a medida que el rendimiento de producción lo permita, modelos de las Tesla y otras tarjetas mucho más potentes.
Como curiosidad, a continuación tenéis cuál sería una aproximación a su rendimiento en juegos si usara unos controladores GeForce —que no los usa—, sin tener en cuenta cambios respecto a Turing —que las GeForce de tipo Ampère las tendrá—. Imaginaos cómo quedaría una tarjeta con un chip A100 totalmente desbloqueado de 8192 núcleos CUDA.
Vía: AnandTech.



