
ARM es la compañía inglesa detrás de la arquitectura de núcleos usada en la mayoría de procesadores de dispositivos móviles, pero no pierde de vista otros ámbitos importantes donde los procesadores de bajo consumo no son menos importantes. El proyecto Trillium de la compañía, anunciado en febrero, aporta una arquitectura de procesador específica para el aprendizaje automático y, específicamente, para realizar inferencias de aprendizaje profundo. Eso significa, por ejemplo, el uso de una red neuronal preentrenada para reconocer objetos en una foto que se meta como entrada de la red neuronal.
El procesador de aprendizaje automático (MLP) que tiene en desarrollo dispone de unidades lógicas y una arquitectura específica para ser eficiente en cuanto a potencia-vatio al realizar inferencias. Eso implica ser eficiente al realizar convoluciones, una de esas palabras que a los ingenieros nos gustan poco pero que son sumamente importantes en el análisis de señales y, en este caso, como método de analizar imágenes. El procesador también hace un movimiento eficiente de los datos entre subsistemas, y da suficiente margen de programabilidad, que son las características claves que indica ARM en su presentación.
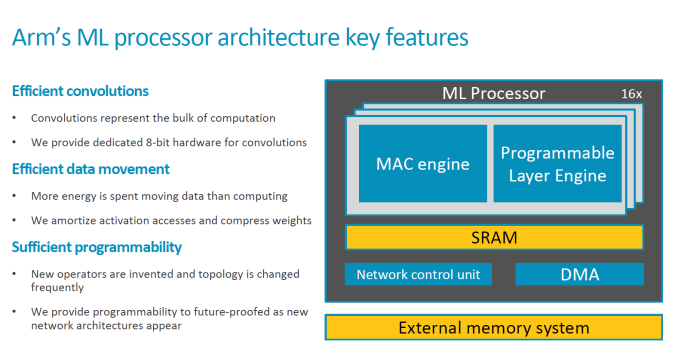
Los chips del proyecto Trillium disponen de uno a dieciséis motores de computación dedicados cada uno a distintas partes de los cálculos, y a su vez incluyen un motor de convolución. Por tanto, es una arquitectura escalable en función de las necesidades específicas del fabricante de dispositivos, como por ejemplo la gama a la que esté orientado.
La zona de memoria SRAM es un bloque común de 1 MB en la que toman y dejan operaciones realizadas, y también disponen de un motor de capa programable ya que no hay por ahora un estándar a la hora de programar y ejecutar las redes neuronales en los procesadores, dando de esta forma cierto margen de actuación a las compañías que quieran usar Trillium. Como es habitual a la hora de hacer inferencias, los datos son de 8 bits ya que no se realiza una elevada precisión en este tipo de cálculos.
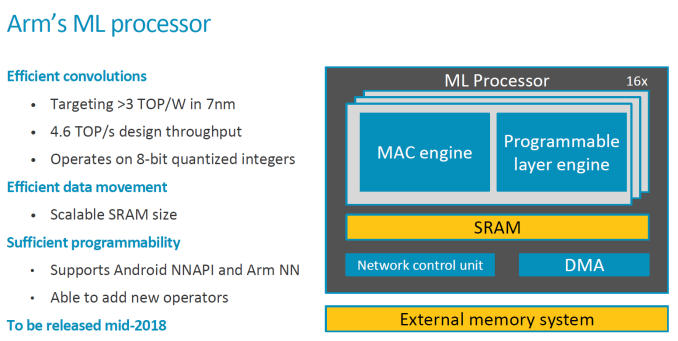
Esta arquitectura está siendo desarrollada para procesos de fabricación a 7 nm y 16 nm —ofertado como POP (processor optimized package)—, que las compañías pueden usar como base para implementaciones específicas que hagan, o realizar una propia totalmente nueva para otros procesos litográficos. Con ello, se reduce hasta un 40 % la superficie del chip con mejoras de potencia del 10 % al 20 %, unido con la compresión de datos para reducir —o aumentar, según se mire— el ancho de banda con la memoria principal del sistema.
Otro apartado que está preoptimizado es el modelo de red neuronal contra el que buscar inferencias de una fuente de entrada —una imagen, por ejemplo—, pero se realiza por anticipado a través de las herramientas que proporciona ARM a los desarrolladores para ello. Con todo ello, y a falta de un procesador real con el que probarlo, ARM promete 3 TOPS/W (teraoperaciones por segundo por vatio de consumo).
Esta arqutiectura y la propiedad intelectual relacionada estará disponible más avanzado el año para su implementación. No es en realidad muy distinta a lo que está usando otras compañías en sus procesadores, como Huawei en el Kirin 970 e incluso el Pixel 2 dispone de una unidad específica para ello, y le lastra que no hay en realidad un único estándar para la ejecución de redes neuronales. Ahora mismo se están usando sobre todo para mejorar la captura de fotografías, o para la estabilización de vídeo grabado.


Vía: AnandTech.

![Encuentran una nueva variante de Spectre; AMD, Intel y ARM ya la tienen solucionada [act.]](https://static-geektopia.com/storage/t/p/245/24537/64x112/intel-bullet.avif)

